
About Me
I am a software engineer building Oracle Cloud Infrastructure. In multi-cloud migration, my team helps customers migrate their compute reousrces and storage data from external cloud providers (AWS, Azure, GCP) to Oracle Cloud. In edge computing, we are building lightweight, resilient services to support real-time data processing, monitoring, storage, and device management across globally distributed nodes.
I received my Master’s degree in Computer Science from Carnegie Mellon University, advised by Prof. Teruko Mitamura. In my previous experiences, I have a diverse academic and industrial background, including Multimodal AI, Model Compression & Efficient ML, Graph Neural Networks, Computer Vision, Natural Language Processing, AI for Healthcare, Data Augmentation, Large-Scale ML, Speech & Audio, and solid software engineering experiences in algorithm design, data structures, problem-solving, and complexity. I’m also active in academics and have served as a reviewer for many top-tier AI/ML conferences, like ICLR, ACL, NeurIPS, etc.
I have been contemplating how machines can transcend their computational limitations to comprehend human intelligence. My aim is to create computationally efficient machine learning and deep learning models and algorithms, establishing the computational foundations that will enable computers to analyze, recognize, and predict subtle human communicative behaviors in social interactions.
Research Interests
Multimodal Machine Learning: representation, alignment, translation, fusion, and co-learning of heterogeneous data
Natural Language Processing: text representation, syntactic parsing, semantic analysis, text generation
Multimodal Sentiment Analysis: text, audio, video, facial expressions, and physiological signals
Computer Vision: image processing, object detection, image segmentation, scene understanding
Services
Conference/Journal reviewer: ACL, ICLR, AAAI, IJCAI, KDD, CVPR, NAACL, NeurIPS, ACMMM, Elsevier, Peerj, MDPI, etc.
Education
- M.S. in Computer Science, Carnegie Mellon University, Dec. 2020
- B.S. in Telecommunications Engineering, Beijing University of Posts and Telecommunications, Jun. 2019
Experience
Oracle
- Software Engineer, Feb 2021 - Current
- Health and AI, Cloud Infrasturcture, Multi-Cloud Migration, Edge Cloud
- Software Engineer, Feb 2021 - Current
GEIRINA
- Machine Learning Engineer Intern, May 2020 - Aug 2020
- Maintained Deep Q Network with OpenAI Gym environment for smart power supply control for power plants
- Machine Learning Engineer Intern, May 2020 - Aug 2020
Tencent
- Machine Learning Engineer Intern, Apr 2019 - Jun 2019
- Responsible for implementing Learn To Rank pipeline in WeChat AI
- Machine Learning Engineer Intern, Apr 2019 - Jun 2019
Oracle
- Full Stack Software Engineer Intern, Sep 2018 - Feb 2019
- Created automation testing methods for testing UI and API actions in frontend and backend.
- Full Stack Software Engineer Intern, Sep 2018 - Feb 2019
Projects & Publications
Project 1: Cellular Macromolecules and Image Classification by Advanced Neural Network Strategies

#Imbalanced Data, #Cryo-Electron Tomography, #Image Classification, #Computational Biology
- Publications
- Ziqian Luo, Xiangrui Zeng, Min Xu, “Deep Learning-Based Strategy for Macromolecules Classification with Imbalanced Data from Cellular Electron Cryotomography,” Proc. of IJCNN’19, Budapest, 2019.
- Xueting Pan, Ziqian Luo, Lisang Zhou, “Comprehensive Survey of State-of-the-Art Convolutional Neural Network Architectures and Their Applications in Image Classification,” In Journal of Innovations in Applied Engineering and Technology, 1(1), 1–16, 2022.
- Feiyang Chen, Ziqian Luo, Nan Chen, Hanyang Mao, Hanlin Hu, Ying Jiang, Xueting Pan, Huitao Zhang, “Assessing Four Neural Networks on Handwritten Digit Recognition Dataset (MNIST), “ In Journal of Computer Science Research, 6(3), 17–22, 2024.
Project 2: Unified AI Framework for Multimodal Multimedia Analysis and Efficient Distributed Computing
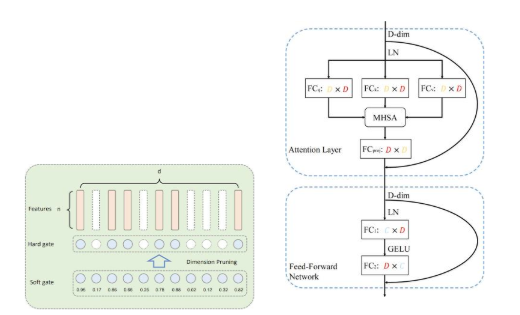
#Vision Transformers, #Model Compression, #Edge Computing, #Resource Optimization, #Knowledge Distillation
- Publications
- Feiyang Chen, Ziqian Luo, Yanyan Xu, Dengfeng Ke, “Complementary fusion of multi-features and multi-modalities in sentiment analysis,” Proc. of the Thirty-fourth AAAI workshop, New York, 2020.
- Xueting Pan, Ziqian Luo, Lisang Zhou, “Navigating the Landscape of Distributed File Systems: Architectures, Implementations, and Considerations,” In Journal of Innovations in Applied Engineering and Technology, 2(1), 1–12, 2023.
- Feiyang Chen, Ziqian Luo, Lisang Zhou, Xueting Pan, Ying Jiang, “Comprehensive Survey of Model Compression and Speed up for Vision Transformers,” In Journal of Information, Technology and Policy, 1(1), 1–12, 2024.
Project 3: Audio Sentiment Analysis by Deep Learning Models
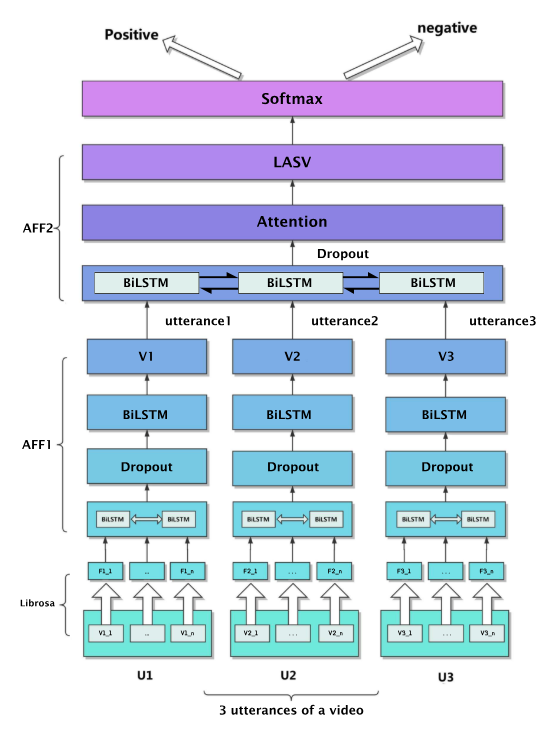
#Multimodal Sentiment Analysis, #Emotion Recognition, #Deep Fusion Models
- Publications
- Ziqian Luo, Hua Xu, Feiyang Chen, “Audio Sentiment Analysis by Heterogeneous Signal Features Learned from Utterance-Based Parallel Neural Network,” Proc. of the Thirty-third AAAI workshop, Honolulu, 2019.
- Ziqian Luo, Hua Xu, Feiyang Chen, “Utterance-Based Audio Sentiment Analysis Learned by a Parallel Combination of CNN and LSTM,” arXiv preprint, 2018.
- Feiyang Chen, Ziqian Luo, “Sentiment Analysis using Deep Robust Complementary Fusion of Multi-Features and Multi-Modalities,” arXiv preprint, 2019.
- Feiyang Chen, Ziqian Luo, “Learning robust heterogeneous signal features from parallel neural network for audio sentiment analysis,” arXiv preprint, 2019.
Project 4: Innovative AI-Driven Summarization and Multimedia Generation Framework

#Pre-trained Models, #Knowledge Graph, #Natural Language Processing
- Publications
- Ziqian Luo, “Knowledge-guided Aspect-based Summarization,” Proc. of the International Conference on Communications, Computing and Artificial Intelligence CCCAI, 2023.
- Lisang Zhou, Ziqian Luo, Xueting Pan, “Machine learning-based system reliability analysis with Gaussian Process Regression”, In Journal of Computational Methods in Engineering Application, 3(1), 1–23, 2023.
- Ziqian Luo, Feiyang Chen, Xiaoyang Chen, Xueting Pan, “A Novel Framework for Text-Image Pair to Video Generation in Music Anime Douga (MAD) Production”, In Journal of Artificial Intelligence Advances, 2024
Project 5: Advancing Question Generation and Mathematical Reasoning: Integrating Visual and Textual Data
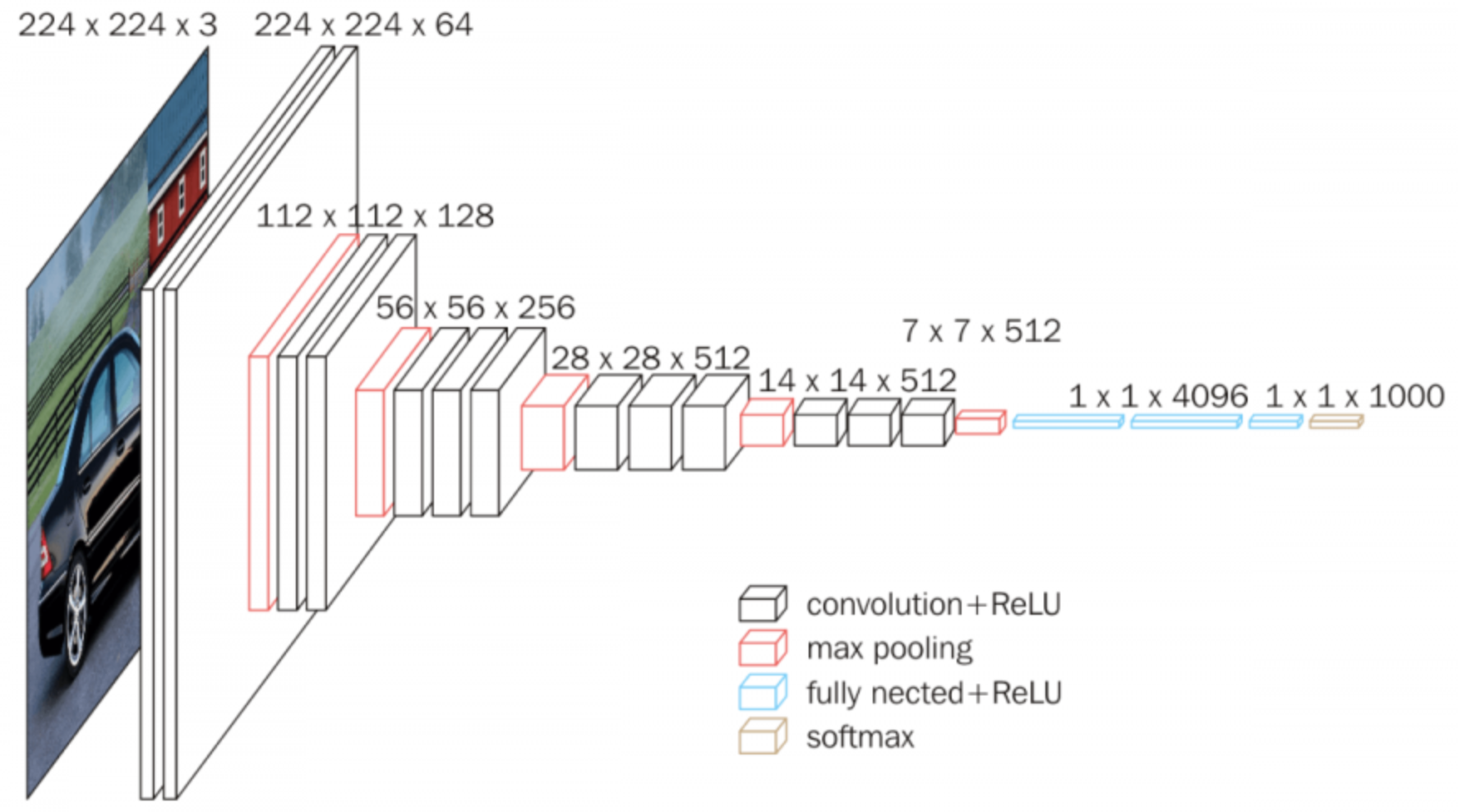
#Multimodal AI Integration, #Visual Question Generation, #Enhanced Mathematical Reasoning
- Publications
- Ziqian Luo, Xueting Pan, “Advancing Mathematical Reasoning in AI: A Comprehensive Approach with the MathQA Dataset,” HAL preprint, 2024.
- Ziqian Luo, Xueting Pan, “Visual Question Generation on VQA Dataset,” HAL preprint, 2024.
Project 6: Transformative AI Innovations for Multimedia Creation Security Enhancement and Efficient Data Processing
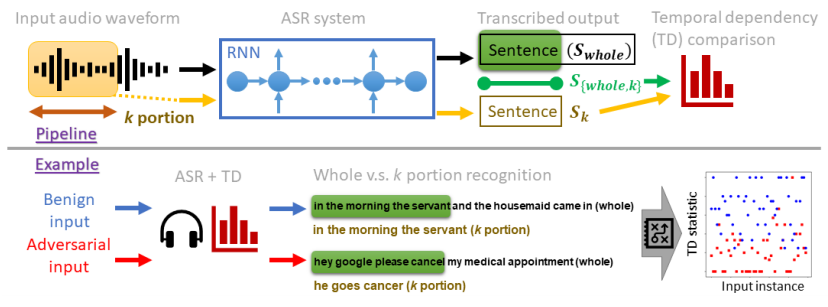
#Multimodal Video Synthesis, #Speech Security and Adversarial Defense, #NLP Data Processing Framework
- Publications
- Ziqian Luo, Xueting Pan, “A Multi-Modal Framework for Text-Image to Video Synthesis with Enhanced Artistic Control,” HAL preprint, 2024.
- Ziqian Luo, “Generalizing Data Processing for Natural Language Processing Tasks,” HAL preprint, 2024.
- Ziqian Luo, Xueting Pan, “Defense Against Adversarial Attacks on Speech Systems,” HAL preprint, 2024.